Revision: 6-13-09
Intro
In my last semester of college, I had the opportunity to do a parallel computing "directed study" with a couple other students using the CS department's lab full of Fedora (basically Redhat) machines. Unfortunately, my group members had both motivational and scheduling problems, so not much got done for the first couple months of this project. Actually, no actual code got written until I gave up on the rest of the group and went Manhattan-Project style on it in the last couple weeks. So this isn't pretty, but it's hopefully helpful to someone and certainly was a learning experience.
There really wasn't much of a goal to this project besides running some parallel code on several different configurations and benchmarking performance. I gravitated toward PVM (Parallel Virtual Machine) early on in the project as it was nearly the exact implementation of a platform-independent master/slave clustering program that I had envisioned. Unfortunately, much time was wasted trying to get RSH (Remote Shell) to work with PVM and learning how to work with Linux's quirks (like how you need to switch to root for almost everything). Eventually, as aforementioned, I just had to go it alone with an ill-conceived parallel mergesort program. It certainly worked, but the speedup was decidedly underwhelming from too much data transmit latency and not enough calculation time.
Below, I have the final Powerpoint presentation that I gave (with notes included). Also, the code for both versions of the mergesort are available; though, I'd recommend only using them as a base for other algorithms or only a mergesort for testing purposes.
Presentation
Notes
| 2. |
 The Choice of PVM - The slide pretty much says it all. As mentioned in the intro, PVM embodied what I thought was the most straight-forward and portable way to implement a cluster. And it required no modifications to work on multicore configurations, as well.
The Choice of PVM - The slide pretty much says it all. As mentioned in the intro, PVM embodied what I thought was the most straight-forward and portable way to implement a cluster. And it required no modifications to work on multicore configurations, as well.
|
| 3. |
 Setup Problems - Being that I had only mediocre Linux experience going into this project (from maintaining my website and a Unix Admin class), there were some significant learning curve issues while trying to get PVM to even run and connect to other nodes. Some problems also arose from the spattering of PVM documentation on the web of varying degrees of insightfulness, quality, and experience level.
Setup Problems - Being that I had only mediocre Linux experience going into this project (from maintaining my website and a Unix Admin class), there were some significant learning curve issues while trying to get PVM to even run and connect to other nodes. Some problems also arose from the spattering of PVM documentation on the web of varying degrees of insightfulness, quality, and experience level.By far the most perplexing problem was the inability of RSH to work with PVM. Even the life-long Unix fanboy professors couldn't figure that one out. Luckily, PVM gets the path to RSH from an environmental variable that can be changed to SSH. And although group scheduling problems led to some of the team's lack of motivation, I doubt the others would have been of much use regardless. I also had to deal with problems stemming from the lab's use by other students, such as: Fedora being reinstalled on the master machine and the NIS server being removed from one machine's fstab. |
| 4. |
 Solutions - As mentioned last slide, SSH (Secure Shell) was the solution to getting PVM to communicate with other machines. However, it requires a pre-shared key to be given to all the slave machines, which is a bit of a hassle. See the reference section for great guide that helped me get through SSH setup.
Solutions - As mentioned last slide, SSH (Secure Shell) was the solution to getting PVM to communicate with other machines. However, it requires a pre-shared key to be given to all the slave machines, which is a bit of a hassle. See the reference section for great guide that helped me get through SSH setup.Also, installing VMWare on my home PC and using it to mount an installation of Fedora was a huge help. It allowed me to get more coding done in a day at home than I would a couple afternoons a week in the lab. Of course, I still had to take the code to the lab for the final benchmarks. |
| 5. |
 This is the install script I came up with to roll out the installation of PVM across the lab. The main points to note are using YUM to install, setting the environmental variables correctly, and generating and distributing SSH keys.
This is the install script I came up with to roll out the installation of PVM across the lab. The main points to note are using YUM to install, setting the environmental variables correctly, and generating and distributing SSH keys.
|
| 6. |
 The Program: Parallel Merge/Quicksort Hybrid - The choice of doing a sort in parallel was made mostly because of the simplicity of the algorithm. I really didn't want to spend a lot of time bogged down in making a fancy algorithm when I just wanted some benchmarks. I also didn't want to copy someone else's code, because that's just not how I roll.
The Program: Parallel Merge/Quicksort Hybrid - The choice of doing a sort in parallel was made mostly because of the simplicity of the algorithm. I really didn't want to spend a lot of time bogged down in making a fancy algorithm when I just wanted some benchmarks. I also didn't want to copy someone else's code, because that's just not how I roll.The Mergesort was used because it essentially divides the data up into equal parts, which could be made to run in parallel rather easily. Once a slave node receives its data, it doesn't even matter what sort you use to finish the calculation. I used a Quicksort because that function is in C's stdlib already and is probably very well optimized. |
| 7. |
 Algorithm - During the presentation, I thought it was most helpful to draw the algorithm out on the board and step the audience through the process. I've attempted to recreate those scribblings below. (Read the slide for an explanation.)
Algorithm - During the presentation, I thought it was most helpful to draw the algorithm out on the board and step the audience through the process. I've attempted to recreate those scribblings below. (Read the slide for an explanation.)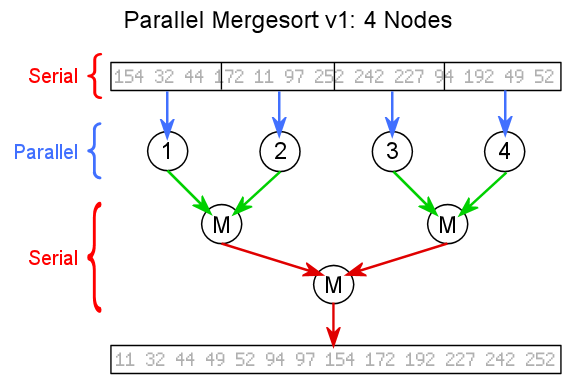 Blue: Data Transmit, Green: Data Receive, Red: Data Kept |
| 8. |
 Problems with Algorithm - Not long into coding the parallel mergesort, I realized that the algorithm had an intrinsic drawback in the present implementation. As the number of parallel nodes increases, the number of subsequent merges on the master node increases. This obviously doesn't scale up well and will eventually take less time in serial than parallel as the number of nodes increases.
Problems with Algorithm - Not long into coding the parallel mergesort, I realized that the algorithm had an intrinsic drawback in the present implementation. As the number of parallel nodes increases, the number of subsequent merges on the master node increases. This obviously doesn't scale up well and will eventually take less time in serial than parallel as the number of nodes increases.Even though the merges are O(n), in this algorithm it would be O(n*Log2(x)) for a total time of O((n/x)*Log(n/x)) + O(n*Log2(x)), where x is the number of nodes and n is the size of the data set. Unfortunately, this equation predicts the fastest the algorithm will get is with only 8 nodes for a theoretical speedup of 3.09. At 16 nodes, the speedup would be less at 2.95. |
| 9. |
 Even with the scalability problems of the completed algorithm, I decided to benchmark the program anyways to see how PVM would perform in a best case scenario--that is, if the master only sends the data to slaves, the slaves do a quicksort, and then the slaves return the sorted data to the master.
Even with the scalability problems of the completed algorithm, I decided to benchmark the program anyways to see how PVM would perform in a best case scenario--that is, if the master only sends the data to slaves, the slaves do a quicksort, and then the slaves return the sorted data to the master.This slide shows the raw output from this first version of the program. The run shown was done on a multicore (4 proc) machine; that's the reason that every task reports running on the same hostname but taking roughly the same time each. |
| 10. |
 Parallel Mergesort v1: Cluster vs Multicore - This slide plots the speedup of each run for the number of tasks used, comparing runs on a quad-core machine against a cluster of machines. The number of items in the data set is also indicated, such that 20M means 20 million items. Again, this program doesn't actually merge the received sorted data sets; it was just used to get a grasp of the best case performance. You'll notice that while the multicore configuration has roughly linear speedup, the speedup of the cluster is halved.
Parallel Mergesort v1: Cluster vs Multicore - This slide plots the speedup of each run for the number of tasks used, comparing runs on a quad-core machine against a cluster of machines. The number of items in the data set is also indicated, such that 20M means 20 million items. Again, this program doesn't actually merge the received sorted data sets; it was just used to get a grasp of the best case performance. You'll notice that while the multicore configuration has roughly linear speedup, the speedup of the cluster is halved.
|
| 11. |
 Parallel Mergesort v1: Individual Host Performance - This graph merely shows the calculation time of the individual nodes in the cluster, using hostnames as identifiers. All the times are about the same except notably Sagitarius as it was the master and Gemini as it was the quad-core machine. Although the mergesort wasn't specifically written to support multicore parallel processing, it could be that either PVM is threaded in a way that takes advantage of the multiple cores or the clock speed was higher than the other machines'.
Parallel Mergesort v1: Individual Host Performance - This graph merely shows the calculation time of the individual nodes in the cluster, using hostnames as identifiers. All the times are about the same except notably Sagitarius as it was the master and Gemini as it was the quad-core machine. Although the mergesort wasn't specifically written to support multicore parallel processing, it could be that either PVM is threaded in a way that takes advantage of the multiple cores or the clock speed was higher than the other machines'.
|
| 12. |
 Second Attempt: Recursion in Parallel - To overcome the scalability problem in the first version of the parallel mergesort, I decided to make the entire algorithm parallel by using the mergesort's inherent recursion. In this way, every merge is done in parallel except the final merge.
Second Attempt: Recursion in Parallel - To overcome the scalability problem in the first version of the parallel mergesort, I decided to make the entire algorithm parallel by using the mergesort's inherent recursion. In this way, every merge is done in parallel except the final merge.The specifics of this algorithm are probably not as complex as they may seem. First, a list of available nodes in PVM is created; this is essentially the only major function done by the master program. Then the master sends the data (the unsorted list) and node list to the first slave node in the list (itself). Every slave has the same functions. They split the received data and node list in half and send the second halves to the first node in the second half of the node list until there are no more nodes in the node list. At that point, the slave node sorts its remaining part of the data and sends it back to its parent. If the slave has a child, it will wait for the child to send its data before then proceeding to merge the two halves, after which it will return the sorted data to its parent. 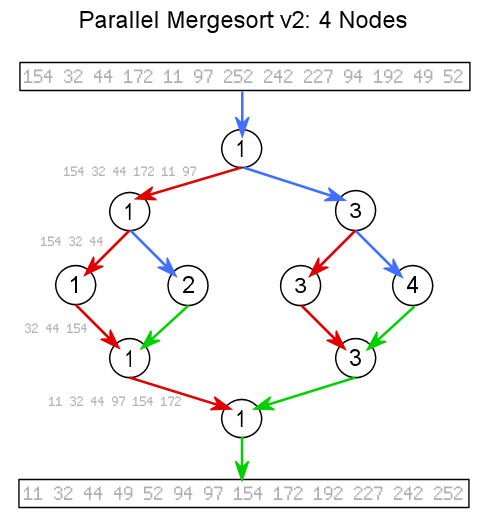 Blue: Data Transmit, Green: Data Receive, Red: Data Kept |
| 13. |  More Problems - Unfortunately, version 2 of the program didn't work as well as theorized; never surpassing the serial execution time no matter the number of nodes. And most unfortunately, I had no more days to work on the program. As a last-ditch fix, I lowered the divisor for splitting the data to try and juice any bit of speedup out of the VM. Splitting the data 3:1 seemed to produce the best results, but this obviously reduced the potential parallel speedup to one-third.
More Problems - Unfortunately, version 2 of the program didn't work as well as theorized; never surpassing the serial execution time no matter the number of nodes. And most unfortunately, I had no more days to work on the program. As a last-ditch fix, I lowered the divisor for splitting the data to try and juice any bit of speedup out of the VM. Splitting the data 3:1 seemed to produce the best results, but this obviously reduced the potential parallel speedup to one-third.
|
| 14. |  This slide shows some example output from version 2. It's sorting 10 million items with 4 parallel tasks on 4 different nodes. The node named Sagitarius is the master. This output shows some of the logic used to separate the tasks recursively; for example, notice how Task 2 spawns Task 3
This slide shows some example output from version 2. It's sorting 10 million items with 4 parallel tasks on 4 different nodes. The node named Sagitarius is the master. This output shows some of the logic used to separate the tasks recursively; for example, notice how Task 2 spawns Task 3
|
| 15. |  This slide merely illustrates that the program does indeed work as intended, producing a sorted list. If told to sort 50 or less items, the program will output the random list after generating it unsorted and after receiving it back sorted.
This slide merely illustrates that the program does indeed work as intended, producing a sorted list. If told to sort 50 or less items, the program will output the random list after generating it unsorted and after receiving it back sorted.
|
| 16. |  Parallel Mergesort v2: Cluster
Parallel Mergesort v2: ClusterThis graph shows the abysmal speedup of version 2 on a cluster of machines. The performance doesn't even come close to the theoretical speedup limit of 2.66 with 8 nodes (1/3 * 8). |
| 17. |  Parallel Mergesort v2: Multicore
Parallel Mergesort v2: MulticoreThe speedup fared only slightly better on the quadcore machine. |
| 18. |  Parallel Mergesort v2: Cluster vs Multicore
Parallel Mergesort v2: Cluster vs MulticoreThis is just the same data from the last two slides plotted together. |
| 19. |  Parallel Mergesort v2: Time Breakdown - This slide is rather baffling. It shows the relative execution time taken up by communication latency, wait time, and actual calculations. Considering the unimpressive speedup of the program, one would think that either communication latency or wait time would have contributed more significantly to the overall execution time, but alas they do not. This leaves me only to speculate on what the phantom performace drain is. My intuition tells me it may have something to do with the memory management and large data sets. I'm betting that with only a few minor fixes, this program could certainly at least double its current speedup.
Parallel Mergesort v2: Time Breakdown - This slide is rather baffling. It shows the relative execution time taken up by communication latency, wait time, and actual calculations. Considering the unimpressive speedup of the program, one would think that either communication latency or wait time would have contributed more significantly to the overall execution time, but alas they do not. This leaves me only to speculate on what the phantom performace drain is. My intuition tells me it may have something to do with the memory management and large data sets. I'm betting that with only a few minor fixes, this program could certainly at least double its current speedup.
|
| 20. |  Future Optimizations - Although the phantom performance drain is certainly the most pressing issue for this program, there are a couple of other optimizations that could be made (if I ever had the motivation and equipment to do such a thing again). One being that the program has no support for multicore machines, which are becoming quite ubiquitous of late. Machines could be given more data to compute based on the number of cores they have; or for a more heterogeneous cluster, based on the CPU speed as well.
Future Optimizations - Although the phantom performance drain is certainly the most pressing issue for this program, there are a couple of other optimizations that could be made (if I ever had the motivation and equipment to do such a thing again). One being that the program has no support for multicore machines, which are becoming quite ubiquitous of late. Machines could be given more data to compute based on the number of cores they have; or for a more heterogeneous cluster, based on the CPU speed as well.Another excellent optimization would be to thread the program to reduce waiting. Creating a thread specifically for waiting for data return from children could significantly reduce wait times, allowing for a more appropriate data partitioning than the 3:1 I was forced to use. |
| 21. |  Conclusion - I didn't bother to calculate the algorithm's performance at the time of the presentation, but apparently the second approach is only somewhat better than the previous one. According to my mediocre-at-best math skills, the function for this algorithm (O((n/x)*Log(n/x)) + O(n*(2-(2/x)))) predicts that this algorithm will reach a point of diminishing speedup after 32 nodes as it approaches 2n (1n for the merge and 1n for the sort). Performance barriers aside, I was and still am convinced that this method is the best way to sort data in parallel given the nature of sorting, wherein every element's position is dependent on every other element's position.
Conclusion - I didn't bother to calculate the algorithm's performance at the time of the presentation, but apparently the second approach is only somewhat better than the previous one. According to my mediocre-at-best math skills, the function for this algorithm (O((n/x)*Log(n/x)) + O(n*(2-(2/x)))) predicts that this algorithm will reach a point of diminishing speedup after 32 nodes as it approaches 2n (1n for the merge and 1n for the sort). Performance barriers aside, I was and still am convinced that this method is the best way to sort data in parallel given the nature of sorting, wherein every element's position is dependent on every other element's position.The slide agrees with this view. It's simply not practical to do such a data-intensive algorithm in parallel unless there is a very minimal communication requirement. Also, PVM is just plain better for computation-intensive algorithms. |
Source Code
Parallel Mergesort v1: As noted earlier, this version doesn't actually sort using a final merge on received data, and as such, it is probably only useful as a base for a more data-parallel algorithm.
Parallel Mergesort v2: This is the final working parallel sort, but as aforementioned, the speedup is horrible. Though, it may be useful as a base for a recursive algorithm that is more computation-intensive (as opposed to data-intensive).
Stopwatch: This is just a class file used by both programs that simplifies execution timers.
Benchmark Results: These are the performance results for both versions of the parallel mergesort plus the graphs of that data.
References
PVM Setup How To Tutorial for Newbies (Backup Mirror)
PVM Users Guide Book
My Paper on Parallel Computing Projects for Academic Environments